




If you're like me, you probably started building Web Apps during the WAMP era; adapting to this new world of Document Databases feels very weird. For me, it oddly felt like moving from an automatic to a stick shift car. While SQL data modeling can take a while to master, you can, by and large, get away with a straightforward heuristic: normalize until you cannot break down your table into more atomic pieces. NoSQL databases, however, seem to give you a lot of freedom, especially when you are used to being guided by this simple rule.
Over the last five years, I’ve worked with Document-based Data Stores in Firebase, Couchbase, and MongoDB, and I'd like to share some heuristics I have picked up that can help you with modeling NoSQL Databases.
TL;DR: Optimize for Key-Value Operations (KVOs)
My number one rule of thumb is to optimize my data modeling for key-value operations. KVO is a term popular in Couchbase, but the principle remains the same in other Database Systems. A document refers to an entry in the database (other databases may refer to the same concept as a row). A document has an ID (primary key in other databases) unique to the document. The document also has a value that contains the actual application data. A KVO, then, refers to any operation that involves direct referencing of a document using its key (as opposed to a query as we would most likely do in SQL).
You should try and model your data in a way that will make it easy for your application only to execute KVOs on that data.
Data on Disk versus Data in Memory
The history of databases goes something like this: we needed to find a way to compact our data on physical storage devices, and columns largely solved this problem, with normalization ensuring that no space is wasted. In applications, however, the industry converged on the idea of object-oriented programming, which saw us model real-world objects in this paradigm. We had to develop a pattern that we named the Object Relational Mapper Pattern or ORM to map the data we stored in databases with the object models we used in our apps.
Today, disk space is not as scarce or expensive. We can store our data in the same format that we model it in the real world. Document Databases tend to be more closely modeled around the objects you natively interact with within your application. Therefore, when modeling Data in NoSQL, you want to know how you will manipulate that data in your application beforehand.
Ok, back to KVOs.
By storing our application (in memory) data in the same way we keep our persisted data, we can benefit from rapid data access. And you generally want to take advantage of this design. Let’s say your application models the annual Grammy Awards; you will want to store your artists in a way that you can retrieve them directly by a sensible unique identifier, perhaps their stage name, as follows:
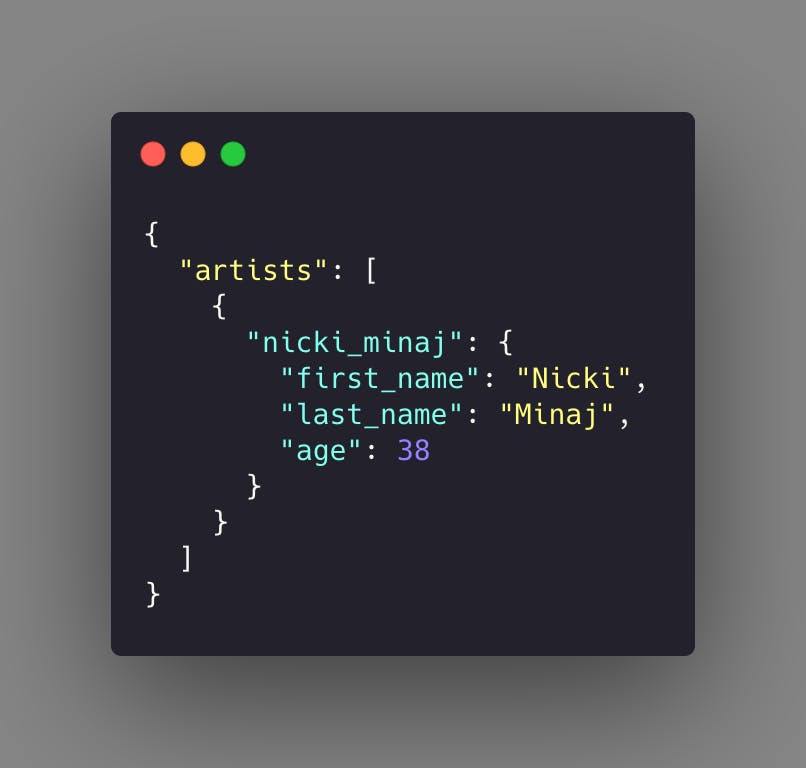
Fetching Nickii’s model then becomes a KVO operation as follows:
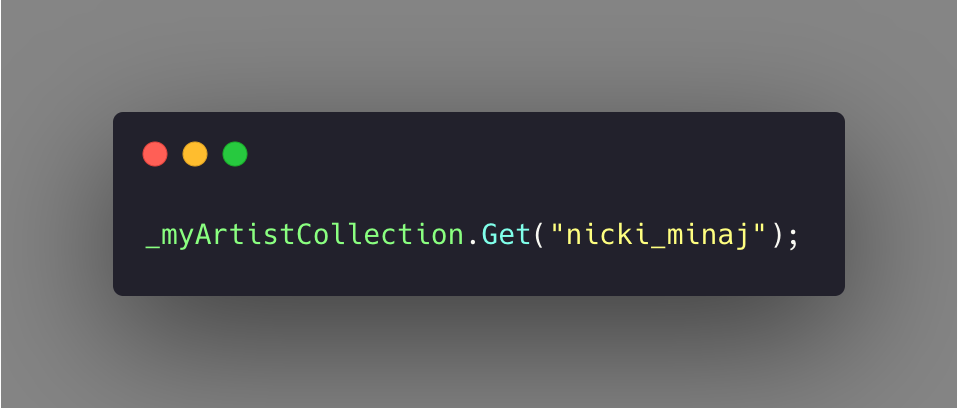
Such a method is going to result in the fastest possible retrieval of your object. Think of this as accessing an element in an array on a specific index.
Designing your application to ensure that you are almost always accessing data this way is not easy. It has a few caveats:
Sensible Unique Identifiers
Designing in this way means that you have to take care when deciding your document identifiers or keys. You can’t just slap an auto-increment option to your IDs as you did in MySQL. Ids have to have some rational business meaning attached to them, and if you don’t already have one, it could point to a potential redesign. Of course, not all documents are going to have a meaningful identifier. Images, for instance, can have a generated value - a GUUID or a timestamp - to identify them uniquely. But for Objects such as employees, identifying them by the business Employee Number is generally preferred to using some arbitrary ID.
Here is a list of sensible identifiers I can think of for popular objects you may model in your application:
- Student Number
- Licence Plate Number
- House Street Number
- Email Address
- Country Code
- ISBN
If you look closely at all these objects, you notice that the physical world in which they exist have already devised a way of identifying them. Instead of making up some random identifier, ask yourself if there is a standard that already exists in the real world to identify items in the modeling data. You will be surprised.
Your applications are not this simple, of course. The data you are modeling is complex and related in intricate ways. For example, you might have a page in your application that shows the Grammy-nominated artists, how many awards they’ve previously won, their latest music videos, and perhaps their Spotify listens. How do you optimize this for a KVO? How do you uniquely identify items under this collection?
This is where the age-old debate of referencing vs. nesting comes about. Do we nest our document with subdocuments? Do we reference another document?
I’ll attempt to answer this question with several principles I’ve learned over the years:
Reference within Subdocument
The challenge in design is that you do not know what data you will reuse. The key to identifying what to reference within a document is to answer who owns that data. In our example, Nicki owns hew award for Best Rap act at the 59th Annual Grammies. But she doesn’t own the Grammys themselves. So it would be sensible to model the data as follows:
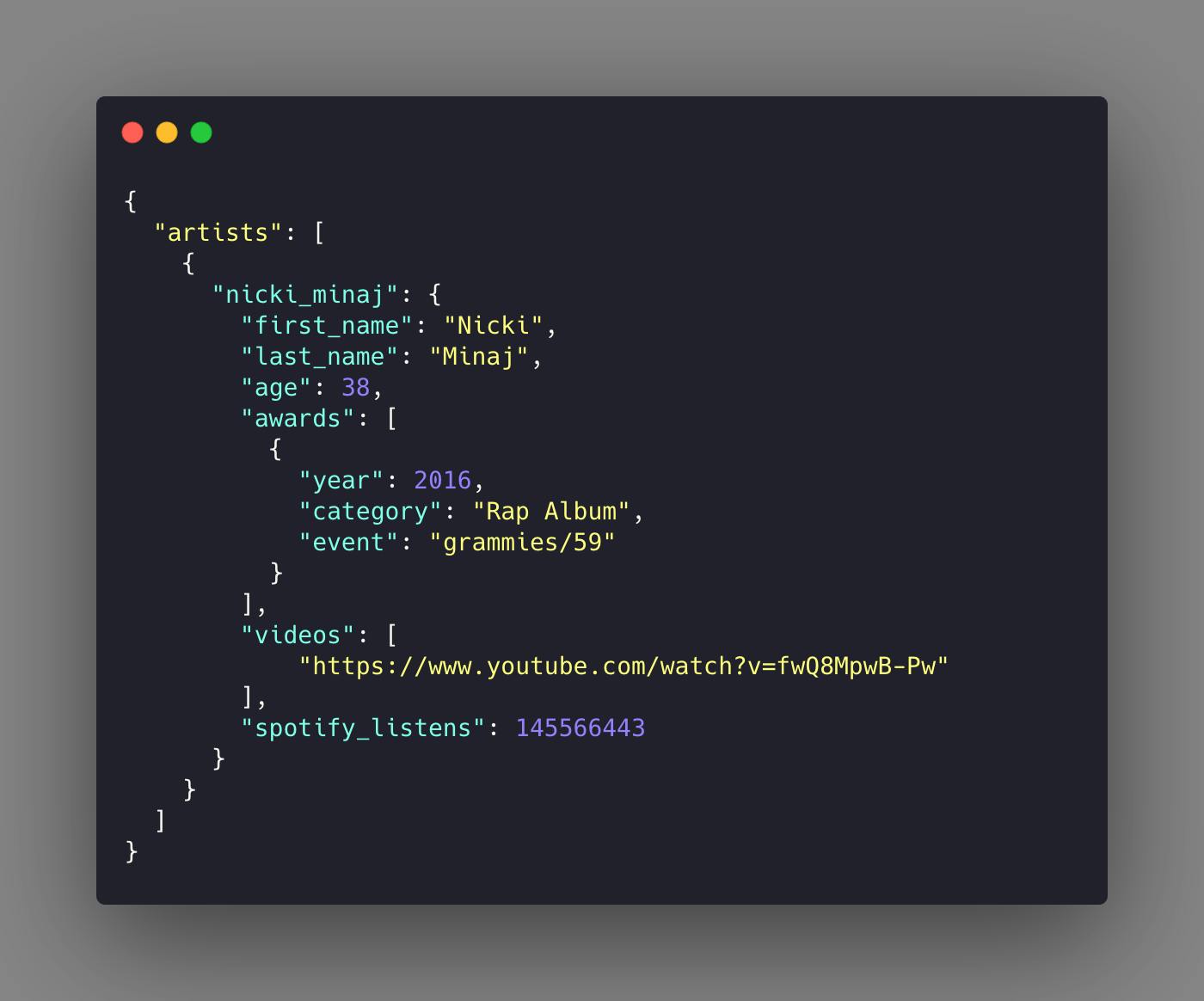
This will allow us to populate our artist summary page efficiently with one KVO since we can derive the grammy’s name from the sensibly chosen identifier. We are also able to link to the specific grammy event if we wanted to in another KVO by modeling the event details as such:
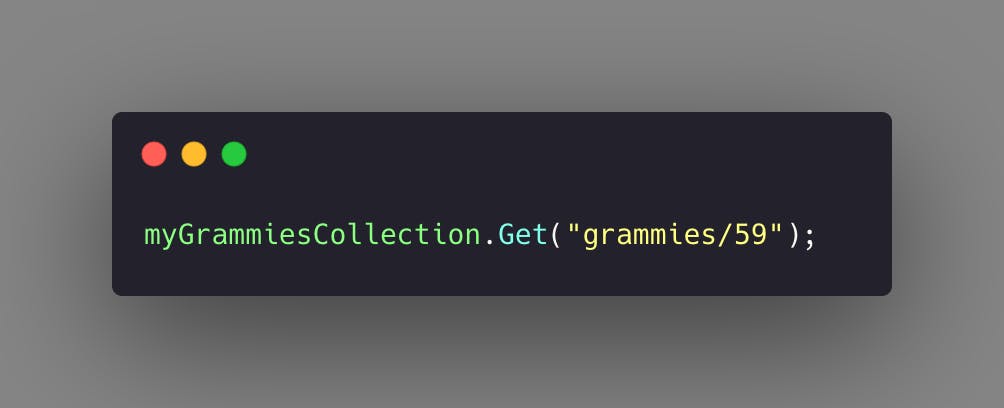
That collection could then be modeled as follows:
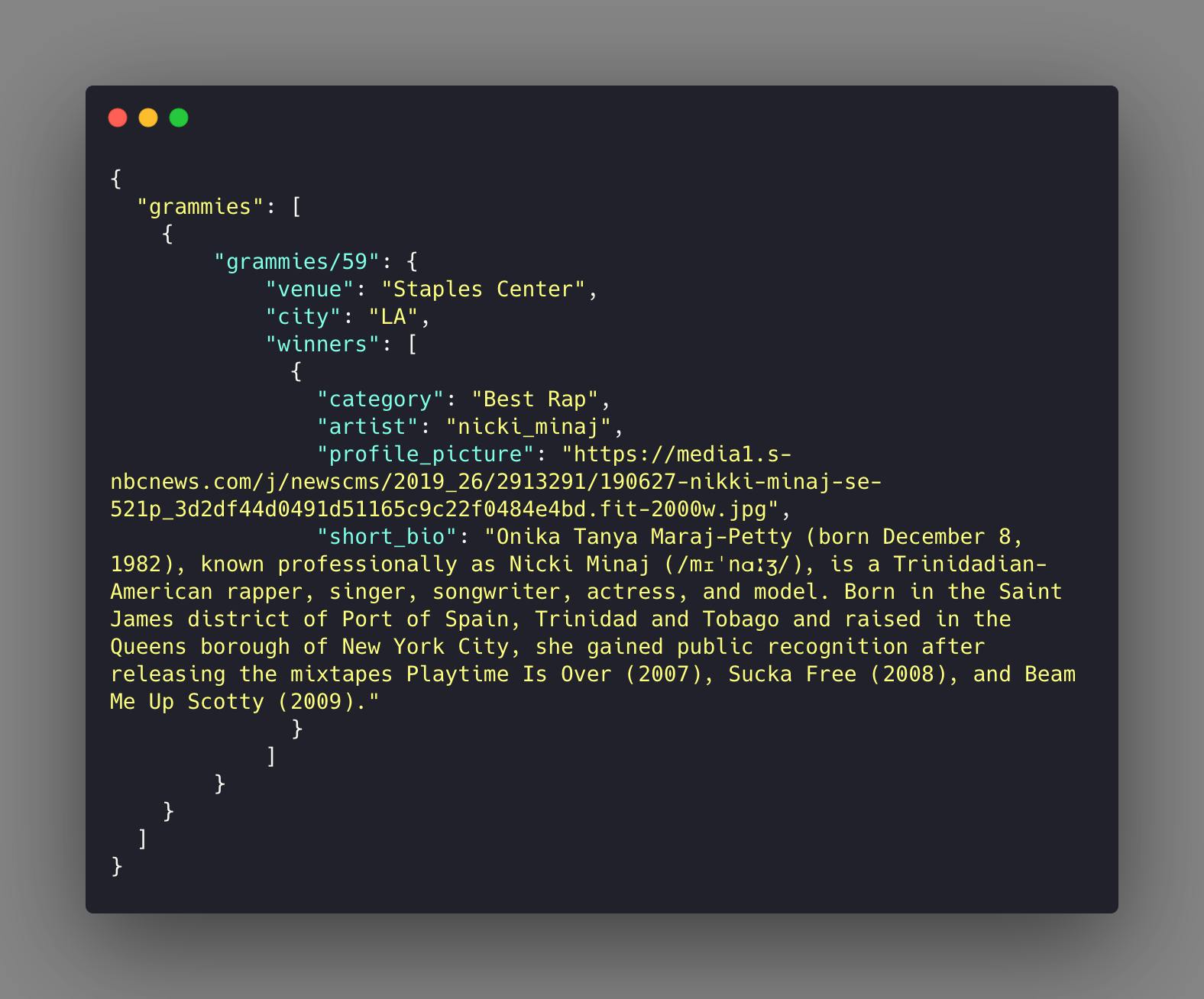
I hear you saying: “Wait, shouldn’t we simply reference Nicki and retrieve that data from there.” And the answer is yes, absolutely! But why should you constrain yourself to keep data in one place if you can have it multiple places with good reason?
Think about the number of times you’ve had to copy certain information across multiple use cases in real life. Your passport-sized photo, for instance, your contact details, etc. It just seems certain information is best copied even if it may have its own file in which it resides. In our case, we will load the grammy’s page with a list of all its winners from one operation, instead of tens of operations as would have been the case if we stuck to strict normalization. So…
Embrace Copying Data
The more you spend time with Document Databases, the more you realize that copying data across multiple places in your schema is not as sinful as initially preached to us. Where performance is concerned, you can more than justify the tradeoff. Today, your application will likely run inside a metered serverless platform as it will on your self-hosted server. In such an environment, the cost for computation can very quickly add up. For instance, a poorly optimized data model will result in an unnecessary number of retrievals, which can exponentially grow as your application becomes more successful. In that situation, copying some data from your artist collection into your grammy’s collection will be a much lesser evil than fetching from the artist collection every time you want to display a Grammy winner for that year.
But what happens when an artist changes their profile image? The reality is that it's not critical for the artist data under the Grammy winners to be 100% in sync with the source of artist data. It is conceivable to run a script every day or even every week that makes sure the data is synchronized. If we did want to ensure real-time consistency, however, then read on.
Use Database Functions Generously
Most Document Database these days offer some eventing facility. Basically, these are like stored procedures that are triggered whenever an event happens. Critically, they can be written in richer programming languages, typically JavaScript, as reactive functions to any data changes. These, in my opinion, are as important a tool in your armory as your codebase itself. In fact, you may check these into version control, as they provide critical business functionality to your applications. Database functions can be ideal for data enrichment and synchronization. Our problem with keeping artists in sync can easily be solved by a Function that gets triggered whenever we update, delete or create an artist.
Perhaps the most valuable use case for these Functions is aggregation. If we want to display a graph in our application showcasing a leaderboard of grammy award winners, we could create the following model:
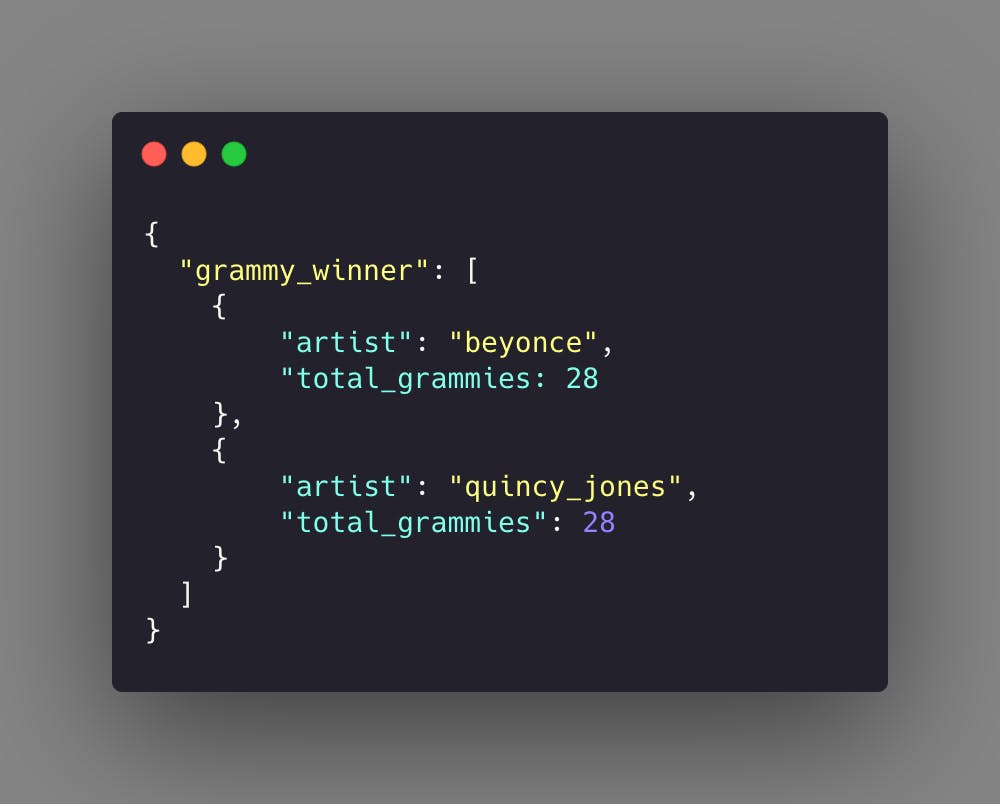
We would use a Database Function here every time artists are updated to calculate their new total Grammy wins and update this collection accordingly. This will allow us the same efficiency in retrieving aggregates, all without reaching out to the familiar SQL!
But…
Of course, when all else fails, a good number of Document Databases these days provide for some querying features. Feel free to use them where it makes sense!